
Yangqing Jia (贾扬清)
me@daggerfs.com

I am currently a research scientist at Facebook, where I lead the effort of building a general, large-scale platform for the many AI applications at Facebook. Previously, I was a research scientist at Google Brain where I worked on computer vision, deep learning and TensorFlow.
I obtained my Ph.D. in Computer Science at UC Berkeley, advised by Prof. Trevor Darrell. During my graduate study I've worked/interned at the National University of Singapore, Microsoft Research Asia, NEC Labs America, and Google Research. I obtained my bachelor and master degrees from Tsinghua University, China.
I am the author of Caffe, which is now a BVLC maintained, open-source deep learning framework. I've worked on the TensorFlow project at Google Brain.
I do have a LinkedIn profile.
Research
My current research topics include:
- Learning better structures for image feature extraction.
- Explaining human generalization behavior with visually grounded cogscience models.
- Making large-scale vision feasible and affordable.
(Most recent publications to be added)
Recent Publications
Links to: [Full List] [Google Scholar]

DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition
J Donahue, Y Jia, O Vinyals, J Hoffman, N Zhang, E Tzeng, T Darrell. arXiv preprint.
[ArXiv Link]
[Live Demo]
[Software]
[Pretrained ImageNet Model]
We evaluate whether features extracted from the activation of a deep convolutional network trained in a fully supervised fashion on a large, fixed set of object recognition tasks can be re-purposed to novel generic tasks. We also released the software and pre-trained network to do large-scale image classification.

Visual Concept Learning: Combining Machine Vision and Bayesian Generalization on Concept Hierarchies
Y Jia, J Abbott, J Austerweil, T Griffiths, T Darrell. NIPS 2013.
[PDF coming soon]
It is marvelous that human can learn concept from a small number of examples, a challenge many existing machine vision systems fail to do. We present a system combining computer vision and cogscience to model such human behavior, as well as a new dataset for future experientation on human concept learning.
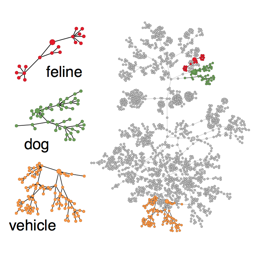
Latent Task Adaptation with Large-scale Hierarchies
Y Jia, T Darrell. ICCV 2013.
[PDF coming soon]
How do we adapt our ImageNet classifiers to accurately classify just giraffes and bears on a zoo trip? We proposed a novel framework that benefits from big training data and adaptively adjusts itself for subcategory test scenarios.

Category Independent Object-level Saliency Detection
Y Jia, M Han. ICCV 2013.
[PDF coming soon]
We proposed a simple yet efficient approach to combine high-level object models and low-level appearance information to perform saliency detection that identifies foreground objects.

On Compact Codes for Spatially Pooled Features
Y Jia, O Vinyals, T Darrell. ICML 2013.
[PDF]
[poster]
[ICLR workshop version]
We analyzed the connection between codebook size and accuracy with the Nystrom sampling theory, and showed how this leads to better pooling-aware codebook learning methods.

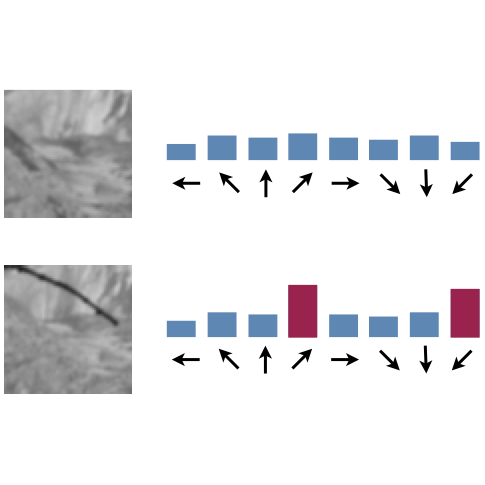
Beyond Spatial Pyramids: Receptive Field Learning for Pooled Image Features
Y Jia, C Huang, T Darrell. CVPR 2012.
[PDF]
[Slides]
[Poster]
We showed the suboptimality of spatial pyramids in feature pooling, and proposed an efficient way to learn task-dependent receptive fields for better pooled features.
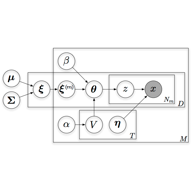
Factorized Multi-modal Topic Model
S Virtanen, Y Jia, A Klami, T Darrell. UAI 2012.
[PDF]
We factorized the information contained in corresponding image and text with a novel HDP-based topic model that automatically learns both shared and private topics.
Heavy-tailed Distances for Gradient Based Image Descriptors
Y Jia, T Darrell. NIPS 2011.
[PDF]
[Supplementary Material]
[Poster]
We examined the heavy-tailed noise distribution of gradient-based image descriptors, and proposed a new distance metric that yields higher feature matching performances.


A Category-level 3-D Database: Putting the Kinect to Work
A Janoch, S Karayev, Y Jia, J Barron, M Fritz, K Saenko, T Darrell. ICCV-CDC4CV workshop 2011
[PDF]
[Dataset]
We presented a dataset of color and depth image pairs collected from the Kinect sensor, gathered in real domestic and office environments, for research on object-level recognition with multimodal sensor input.
Software

Mincepie: lightweighted Mapreduce
A lightweighted mapreduce implementation purely written in Python. It's not the powerful yellow elephant, but is worth 30 minutes' learning time. Check the script that extracts gist features from all ImageNet images!

Decaf is a general python framework for deep convolutional neural networks, relying on a set of scientific computation modules (such as numpy/scipy) to efficiently run CNN models without the need of a GPU. Decaf is still under development but an imagenet classification demo could be checked out here.
Teaching (GSI)

CS188 Artificial Intelligence , spring 2012.
Undergraduate AI course: search, CSP, games, MDP, Reinforcement Learning, Bayes' Nets, HMM, DBN, probabilistic inference, and a fun PacMan challenge.
Won the campus Outstanding GSI Award.
CS281a/Stat241a Statistical Learning Theory , fall 2011.
Graduate level course: graphical models, probabilistic inference, parameter estimation, regression, exponential family, EM and HMM, factor analysis, Junction Tree Algorithm, Monte Carlo, Variational Inference, etc.